OpenClaw 與 Ollama 混合架構實踐:雲端決策與本地執行的分層設計
前言:雲端智慧與本地動力的完美結合
在人工智慧快速發展的時代,如何更有效地利用大型語言模型 (LLM) 變得至關重要。OpenClaw 與 Ollama 的混合架構,正是結合了雲端 LLM 的智慧決策能力與本地 LLM 的高效執行能力,提供了一種創新且經濟高效的解決方案。 本篇文章將深入探討這種分層設計的原理、優勢以及具體的實作方式,讓您了解如何在實際應用中最大化 AI 的潛力。
架構哲學:主腦與外掛的雙層協作
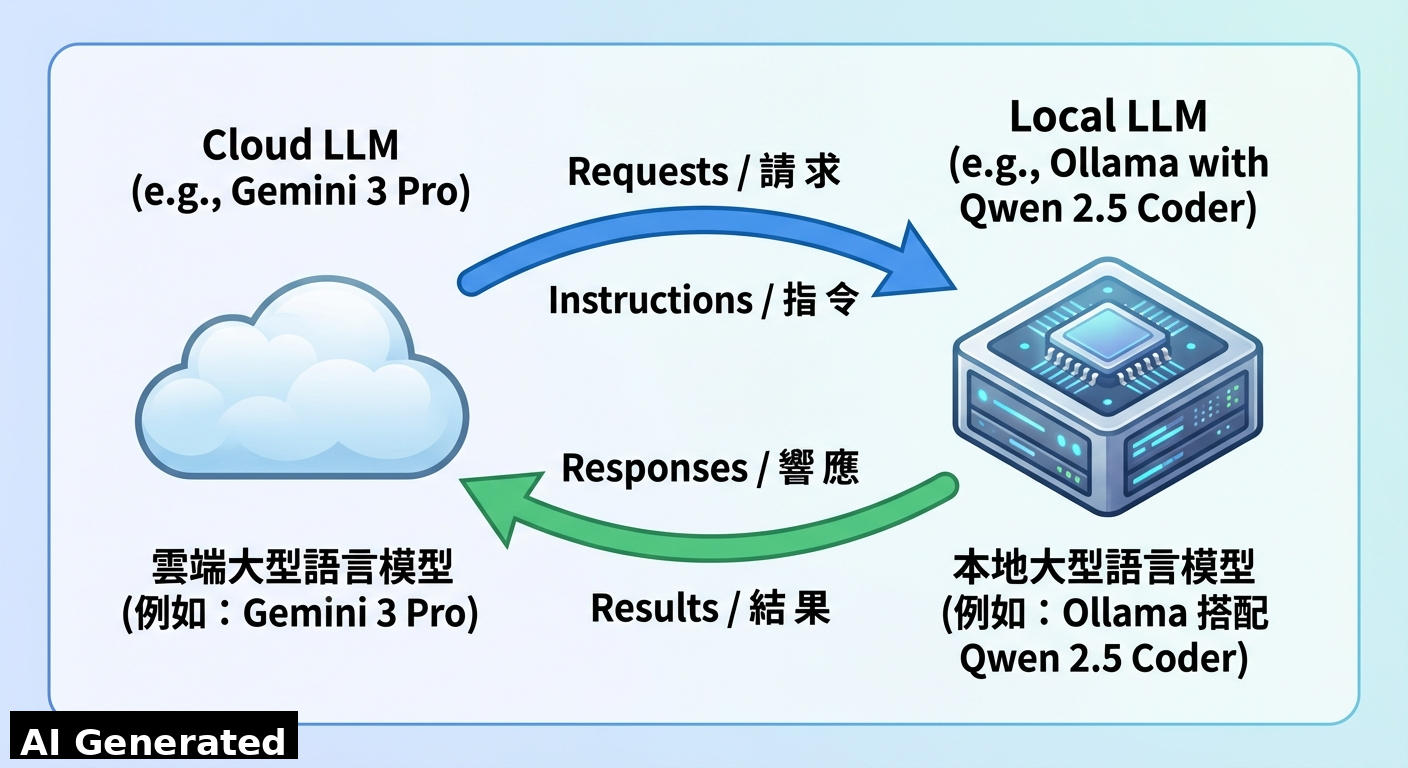
OpenClaw 與 Ollama 的混合架構採用了「主腦 (Cloud LLM) – 外掛 (Local LLM)」的雙層架構,將複雜的任務分解成策略決策和具體執行兩個層面。 想像一下,這就像一個團隊,雲端 LLM 擔任指揮官,負責制定策略和分配任務,而本地 LLM 則像專業的外掛工具,負責執行特定的、需要大量運算的任務。
- 第一層 (Control Plane):雲端 LLM,例如 Google Gemini 3 Pro。它負責處理複雜的邏輯、協調不同的 Skill、理解使用者的意圖,並且做出最終的決策。 這一層就像大腦,負責思考和規劃。
- 第二層 (Execution Plane):本地 LLM,例如 Ollama 搭配 Qwen 2.5 Coder。它專注於執行特定的任務,例如大量程式碼生成、網頁切版、以及處理敏感資料。 這一層就像手和腳,負責執行具體的動作。
這種分層設計的核心理念是讓雲端 LLM 負責需要高度智慧和判斷力的任務,而將計算密集型或對隱私有要求的任務交由本地 LLM 處理,從而達到最佳的性能和成本效益。
混合架構的優勢:成本、隱私、穩定性
OpenClaw 與 Ollama 的混合架構帶來了多項顯著的優勢:
- 成本效益:本地 LLM 執行任務無需支付雲端服務的 token 費用,大幅降低了整體成本。 特別是對於需要大量程式碼生成或數據處理的應用場景,可以節省大量的開銷。
- 隱私合規:敏感的程式碼或個人資料無需上傳到第三方 API,降低了資料外洩的風險,符合嚴格的隱私法規要求。 這對於金融、醫療等對數據安全要求極高的行業尤為重要。
- 穩定性:避免了因本地模型指令遵循能力不足而導致 Agent 邏輯崩潰的問題。 通過將複雜的決策交由雲端 LLM 處理,可以確保整體系統的穩定性和可靠性。
技術實作:Ollama 部署與 OpenClaw 整合
以下是如何在實際環境中部署 Ollama 並與 OpenClaw 整合的步驟:
- Ollama 部署:首先,您需要在本地環境中安裝 Ollama。 可以通過以下命令快速完成安裝:
curl -fsSL https://ollama.com/install.sh | sh安裝完成後,從 Ollama Hub 下載所需的模型,例如 Qwen 2.5 Coder:
ollama pull qwen2.5-coder:7b - OpenClaw 整合:在整合 OpenClaw 時,我們發現直接將 Ollama 設為 Primary Model 可能會遇到
model not allowed的問題,並且可能導致指令遵循能力下降。 因此,最佳實踐是保持openclaw.json的純淨,不將 Ollama 註冊為 Provider。 - 呼叫模式 (The Tool-Use Pattern):將本地 LLM 視為一個外部 API 工具,通過
curl命令直接與之互動。 這種模式稱為 Tool-Use Pattern,允許 OpenClaw 利用本地 LLM 的特定能力,而無需直接將其整合到核心決策流程中。例如,可以使用以下命令來調用 Qwen 2.5 Coder 生成程式碼:
curl -s -X POST http://localhost:11434/api/generate -d '{"model": "qwen2.5-coder:7b", "prompt": "請生成一段 Python 程式碼來計算斐波那契數列"}'
結論:微服務思維與 AI 的未來
通過 API 介面將本地 LLM 視為一種「微服務」而非「大腦」,是平衡智慧與成本的最佳解決方案。 這種方法不僅可以充分利用本地 LLM 的計算能力,還可以確保雲端 LLM 在決策過程中的主導地位,從而實現更高效、更經濟、更安全的 AI 應用。 未來,隨著本地 LLM 的能力不斷提升,我們可以預見這種混合架構將在更多領域得到廣泛應用,為我們的生活和工作帶來更多便利。