自建本地化 AI 工作流:OpenClaw + Ollama + Dify 整合架構深度解析
在當今 AI 應用百花齊放的時代,許多開發者和小型團隊渴望在保護數據隱私和控制成本的同時,利用大型語言模型(LLM)的強大能力。一個常見的解決方案是在虛擬專用服務器(VPS)上自建一套完全本地化的 AI 工作流。本文將深度解析一個由 OpenClaw、Ollama 和 Dify 組成的整合架構,並探討其在資源有限的 VPS 環境(如 Hostinger KVM 2)下的優勢與挑戰。
架構概覽
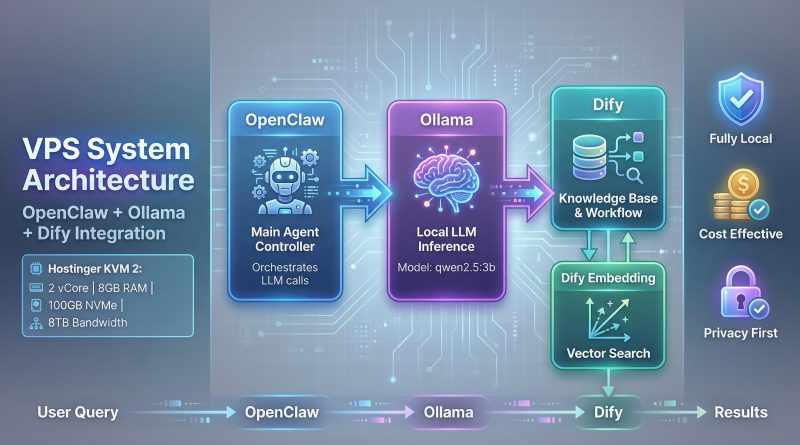
這個系統的核心思想是將 Agent 邏輯、模型推理和知識庫管理三個關鍵環節解耦,並在單一的 VPS 上運行。下圖清晰地展示了各組件之間的協作關係:
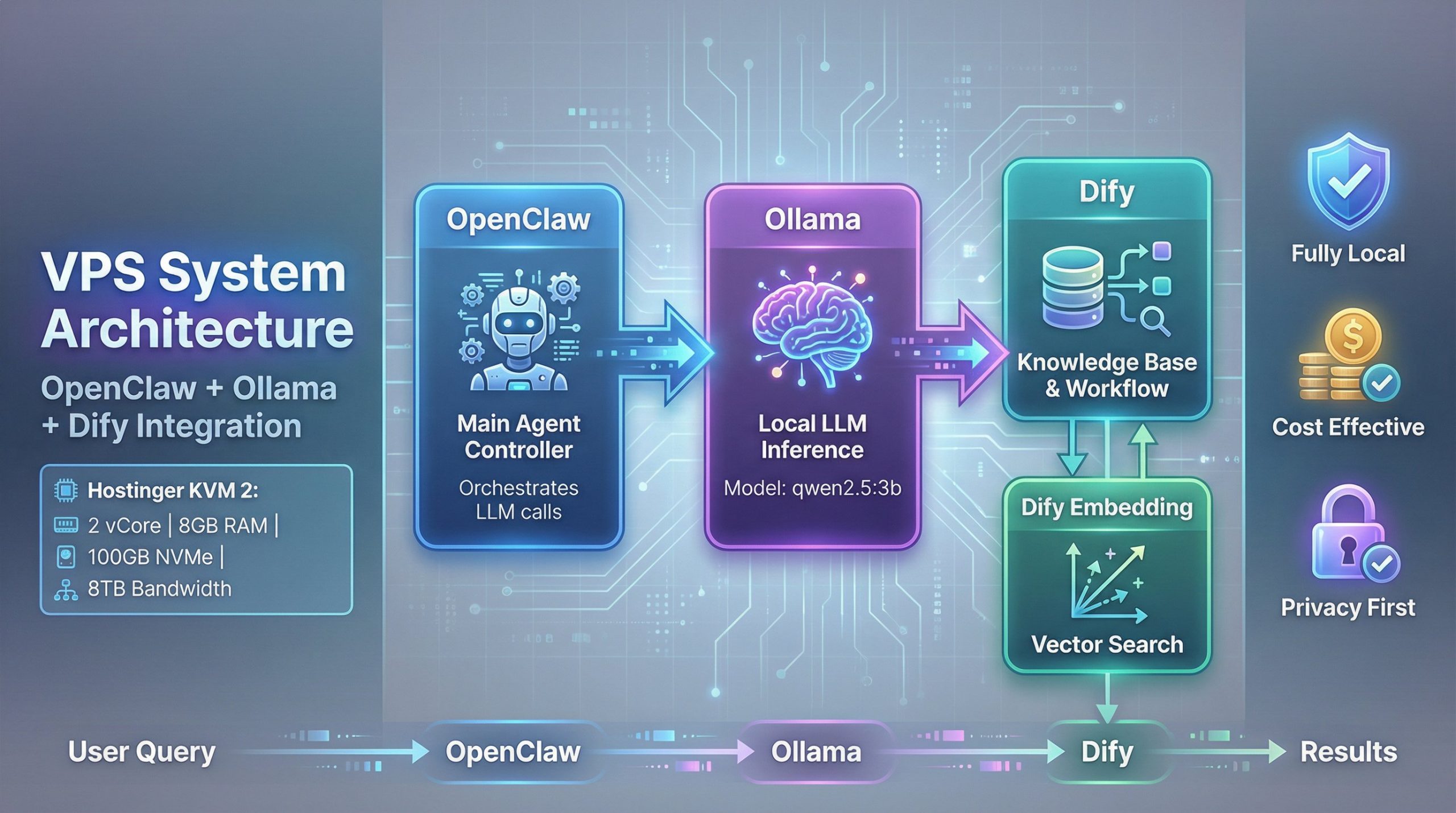
- OpenClaw (主控 Agent):作為系統的大腦,負責接收用戶請求,協調和調用下游服務。
- Ollama (本地 LLM 推理):提供本地化的 LLM 推理能力,讓我們可以運行像
qwen2.5:3b這類開源模型,無需依賴外部 API。 - Dify (知識庫與工作流):一個強大的 LLM 應用開發平台,這裡主要利用其知識庫功能,為 Agent 提供外部知識參考。
- Dify Embedding (向量化服務):負責將知識庫文檔轉換為向量,以實現高效的語義搜索。
數據流從用戶查詢開始,由 OpenClaw 接收,接著調用 Ollama 進行初步處理,並通過 Dify 的 API 檢索相關知識,最終由 Ollama 整合信息生成回覆。
優勢分析
| 優勢 | 說明 |
|---|---|
| 完全本地化與數據隱私 | 這是此架構最吸引人的特點。所有組件和數據都託管在自己的 VPS 上,意味著從用戶查詢到模型生成的所有數據流都在內部循環,完全避免了將敏感數據發送到第三方 API 的隱私風險。 |
| 成本效益顯著 | 相比於按量付費的商業 LLM API,自建架構的主要成本僅為 VPS 的租用費用。對於需要頻繁調用 LLM 的應用場景,長期下來可以節省大量開支。 |
| 高度可控與自定義 | 開發者擁有對整個技術棧的完全控制權。你可以自由選擇或更換 LLM 模型、調整 Dify 的工作流、優化 Embedding 算法,甚至修改 OpenClaw 的 Agent 邏輯,以滿足特定的業務需求。 |
挑戰與考量
儘管優勢明顯,但在資源有限的 VPS(如 Hostinger KVM 2,配置為 2 vCPU cores, 8 GB RAM 和 100 GB NVMe 存儲空間)上部署此架構,會面臨一些現實的挑戰。
| 挑戰 | 說明 |
|---|---|
| 資源管理的挑戰 | LLM 推理是資源密集型任務。即便有 8GB RAM,同時運行 Ollama、Dify 和其他服務時,內存管理依然是一個需要關注的重點。這可能導致推理速度緩慢、系統響應延遲,甚至出現內存溢出(OOM)錯誤,導致服務崩潰。CPU 性能(2 vCore)也會成為處理速度的瓶頸。 |
| 複雜的維護成本 | 與使用單一的 SaaS 服務不同,自建架構需要用戶自行負責所有組件的安裝、配置、更新和故障排除。這不僅需要較高的技術能力,也意味著需要投入額外的時間和精力進行系統維護。 |
| 模型性能的權衡 | 為了在有限的資源下運行,我們只能選擇較小的本地模型(如 3B 參數級別)。雖然這些模型在特定任務上表現不錯,但其綜合能力(如推理、遵循指令的複雜度)通常無法與 GPT-4 等頂級商業模型相比。 |
結論
在 VPS 上自建一套由 OpenClaw、Ollama 和 Dify 組成的本地化 AI 工作流,是一個兼具隱私、成本和控制權的優秀方案。它特別適合那些重視數據主權、具備一定技術能力的開發者、研究人員和小型團隊。
然而,成功部署和穩定運行此架構的關鍵在於資源管理和預期設定。Hostinger KVM 2 的配置(2 vCore, 8GB RAM)為此架構提供了一個相對舒適的運行環境。儘管如此,優化服務配置、監控資源使用,並選擇合適大小的 LLM 模型,依然是確保系統流暢運行的關鍵。對於需要更高性能和穩定性的生產環境,升級 VPS 配置或將不同服務分佈到多個服務器上,將是必要的下一步。
作者:大頭恩 | 發佈:Manus AI